2019年10月27日举行了ICCV会议, 旷视有一些论文被收录, 刚好看到有LLCV组的同事有论文在列, 做的东西也是组内业务所驱动的人像抠图(Image Matting)方向, 所以就把这篇文章给读了一下, 文章结构很清晰, 接下来针对内容做一些记录.
研究内容
- Matting: 同样是抠图, 不同于分割(segmentation)的是, matting更侧重于精细抠图或者更具体地来说, 追求的是发丝级抠图. 应用背景有手机拍照中的的人物背景虚化, pohtoshop的魔棒功能等(据说Adobe马上就要上线这个AI抠图功能了). 与语义分割想要获得更大的感受域不同, matting在trimap区域的regression task更关注的是local信息. 通常, 先由人工指定一个软分割区域trimap, 然后trimap和image一起作为input输入. 输出是每一个pixel属于foreground还是background的概率(0-1之间的连续值).
文章创新点
- trimap+$\alpha$: 传统的matting算法, 先需要经人工指定一个粗糙的trimap, 这个trimap可能是手工标记繁琐的或者是在低分辨率图像上难以实现的. 该文抛弃了这种做法, 直接先在网络中学习出一个trimap, 再依据学习到的trimap去做matting, 这两个过程相互影响相互促进, 会有更好的效果. 文中具体的解释如下,.

网络结构
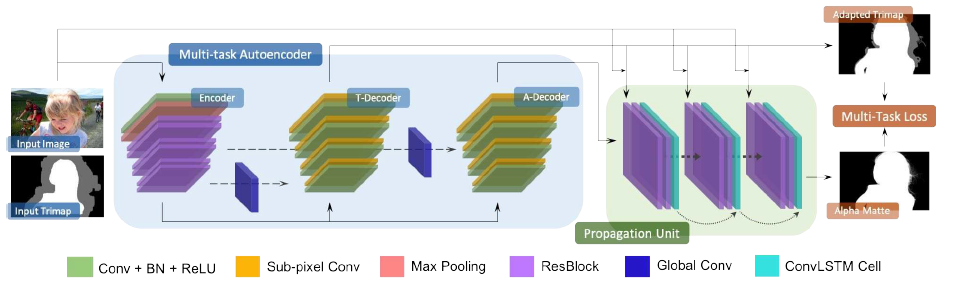
- 简洁地说, 就是一个U-net后面接了一个ConvLSTM模块. 其中, U-net包含两个decoder, 一个decoder负责生成trimap, 一个decoder负责生成$\alpha$. 由于所需要的感受域大小不同, U-net中的shortcuts也不同, 具体到原文句子:
the trimap decoder employs deep and middle layer symmetric shortcuts, and the alpha decoder employs middle and shallow layer symmetric shortcuts.- 用到的一些经典模块:
Global Conv, 即旷视2017年语义分割论文”Large kernel matters”中的大卷积;Sub-pixel Conv, 常用于超分辨问题中的子像素卷积, 在上采样操作中可防止由于插值导致的棋盘状artifact的出现;ConvLSTM Cell, LSTM的卷积版本, 以后可能会被我的工作中用到, 关于它的详细结构后续再专门介绍.
损失函数
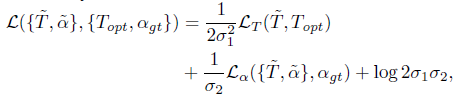
- 其中, trimap的loss是交叉熵, $\alpha$的loss是L1 loss. $\sigma_1$和$\sigma_2$是网络训练中实时可变的训练参数, 具体如何动态调整的还需要看源码才能知道.
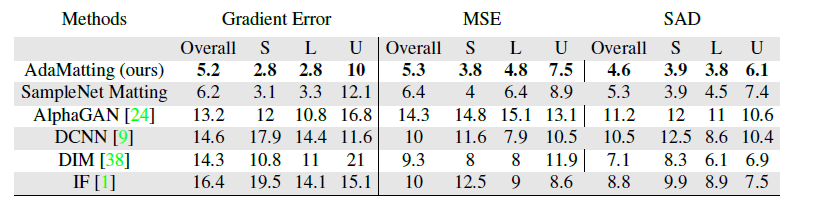
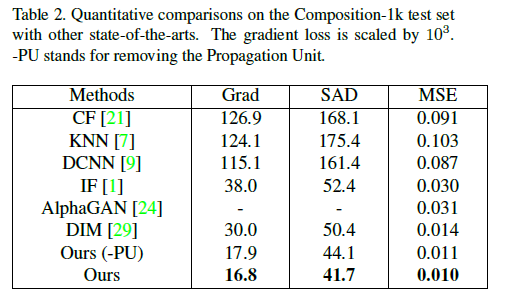
模型效果
- 在
Adobe Composition-1k dataset(431张图)和alphamatting.com(30几张图)上实现了SOTA.
值得学习的地方
U-net+ConvLSTM的使用, 对我的后续研究课题中, 时间序列上的输出有参考意义.