有什么样的数据, 就能训出什么样的丹, 这是我在实习的时候mentor所传授的经验. 经常客户爸爸反馈模型在某些场景下不work了, 我们就需要在训练集中加入bad case下的数据, 或者augmentation做得狠一点, 新一版的模型就能work了. ICCV的这篇oral思路也是一样, 获取真实场景下的数据去训练模型, 接下来做一下记录.
研究内容
- Real datasets & Pyramid kernel network: 在超分辨率问题上, 获取真实场景下的低精度图像, 而不是用高精度图像退化得到的”假低精度图像”, 并提出了拉普拉斯金字塔型的多级超分模型.
文章创新点
- Real datasets: 传统的Super-Resolution(SR)算法, 在处理数据集时, 都是先有高精度图, 在此基础上进行下采样或高斯blur等操作, 获取人为合成的低精度图, 形成”(Low-Resolution)LR-(High-Resolution)HR”数据对. 然而这种人为生成LR的方式是不符合实际场景的, 实际中低精度图的生成要复杂得多. 也就是说, 人造的LR并不是真正的LR. 这样训练出来的模型拿到实际场景下去检验, 效果就会不如人造理想数据集下的效果. 该文提出了一种同时获取HR和LR数据对的方法, 这样的数据集就是高度贴近真实场景的.
- Pyramid kernel network: 传统的SR模型, 输入和输出分别是LR和HR. 该文中提出的模型输入是LR, 输出是每个pixel位置上的reconstruction kernel, 再用输入的频域图与这些kernel做矩阵内积操作, 反拉普拉斯变换后即得到HR. 有点类似于ResNet学习残差的思想, 不直接学习目标值, 而是学习一个间接的中间量.
Real数据集
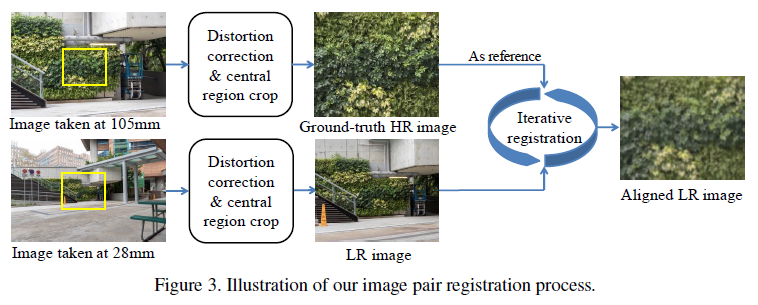 将相机固定在同一位置, 不断地调整相机的焦距, 由此会采集到清晰度不同的图像对. 但同时, 由于焦距的不同, 会有不同的曝光程度以及视场中心飘移等问题, 因此需要后续对选择的ROI进行对齐. 通过不断地迭代优化以下目标函数, 实现图中所示的对齐效果.
将相机固定在同一位置, 不断地调整相机的焦距, 由此会采集到清晰度不同的图像对. 但同时, 由于焦距的不同, 会有不同的曝光程度以及视场中心飘移等问题, 因此需要后续对选择的ROI进行对齐. 通过不断地迭代优化以下目标函数, 实现图中所示的对齐效果.
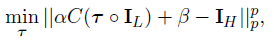 具体的迭代过程, 文中并没有给出详细的推导说明, 只是引了几篇论文, 然后给出了$\tau$的更新规则,
具体的迭代过程, 文中并没有给出详细的推导说明, 只是引了几篇论文, 然后给出了$\tau$的更新规则,
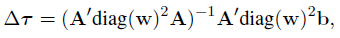 $\tau = \tau + \triangle\tau$
$\tau = \tau + \triangle\tau$
网络结构
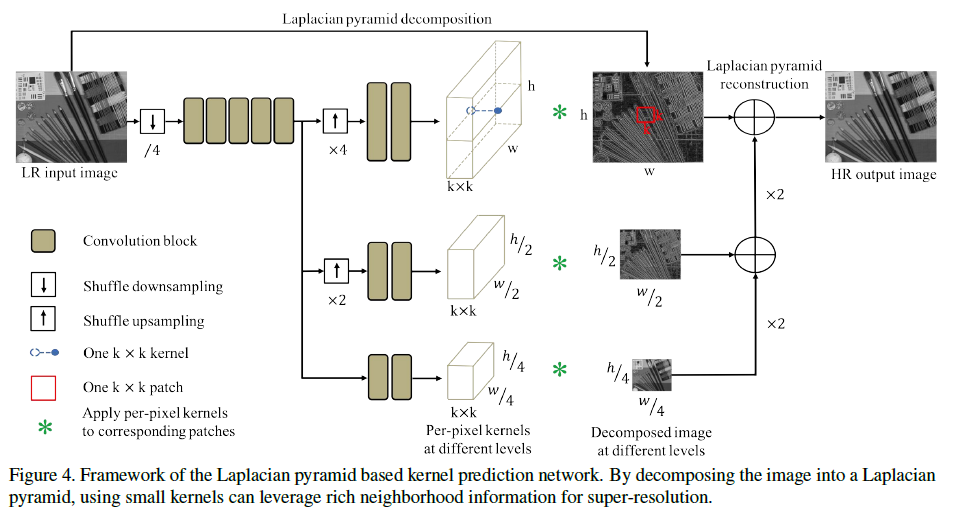
- Laplacian pyramid based kernel prediction network (LP-KPN): 正如前文所述, 该网络预测的是每个LR的pixel对应的$K\times K$卷积核, 每个pixel作用于对应的kernel, 即可得到HR. 这些$K\times K$卷积核以flatten的形式出现在不同scale的输出中, 需要用时reshape成$K\times K$即可. 采用这种方式减少了运算量, 跟感受域的原理类似, 其实K越大, 决定每一点pixel的范围越广, 效果越好, 然而如果不采用金字塔scale的形式, 当K很大时, 网络会变得很大, 计算费时. 文中关于该点的原话:
Benefitting from the Laplacian pyramid, learning three KxK kernels can equally lead to a receptive field with size 4Kx4K at the original resolution, which significantly reduces the computational cost compared to directly learning one 4Kx4K kernel.
损失函数
- 采用常见的$L_2$ loss.
模型效果
- 比较
Real datasaet和Simulated datasets. 采用一些SOTA模型, 比较它们在不同的数据集下的效果, 以此来说明Real datasaet的能力.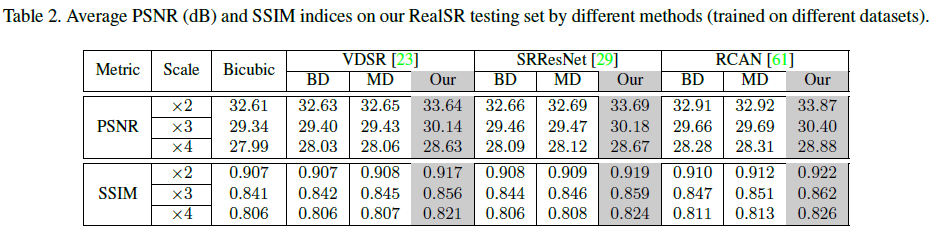
- 比较
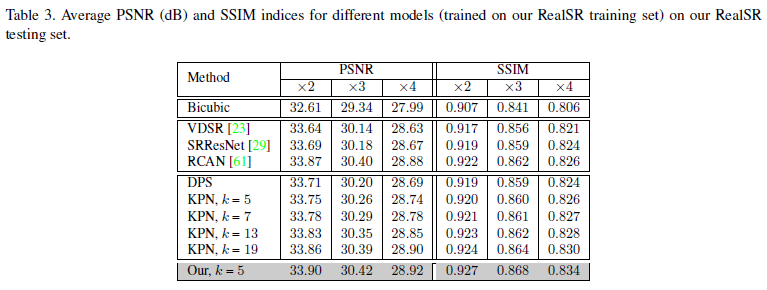
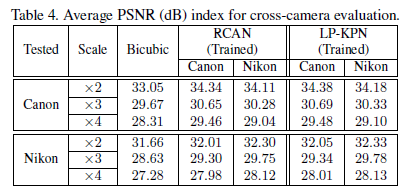
LP-KPN和其它模型. 以此来说明LP-KPN模型的能力.- 比较采集数据所用不同相机的影响. 相机型号不同, sensor会不同, LR-HR的映射关系也会有不同, 以此来说明针对相机的无关性. 训练集和测试集所用的相机不同时, 分数会有所下降, 但是也比bicubic baseline分数高.
- 街景实测. 实践是检验真理的唯一标准. 实际场景下无评价指标, 只定性地看了效果.


总结
- 全文亮点主要在
Real dataset上, 如何巧妙地获得真实数据下的场景是关键. 在算法模型上绞尽脑汁, 可能也比不上训练数据向真实数据靠拢一小步来得实惠.
想起在旷视实习时, 做视频降噪项目, 也是同样的思路, 炼丹前先采数据, 采完数据拿去标定, 标定好了之后合成数据. 与文中那样实采数据拿来训练不同, 我们是合成数据, 怎么合成也有讲究. 会先对真实场景下数据进行数学建模, 然后采benchmark来标定模型中的参数, 最后再利用现有的大数据集, 在原有数据的基础上加上参数化的噪声, 即是符合真实场景下的数据. 虽然可能没有文中数据集那么严格贴近真实, 但是我们做到了近似贴近, 同时享有合成数据数量大的优势.
算法工程师, 首先得是一个数据采集、标定、清洗工程师, 然后需要是一个满足基本要求的开发工程师, 最后才需要是一个炼丹调参工程师. 很惭愧, 我没有在第一条上做得很好, 在第二条上是一片空白, 在第三条上也才刚入门. 不过, 已经从”不知道自己不知道”过渡到了”知道自己不知道”这条道路上, 道阻且长, 还需长期努力.