什么是光流? 字面上的意思就是光的流动. 通过追踪视频前后帧对应像素点之间的位移, 可用于视频防抖, 视频压缩等领域. 曾经见过同事用光流法做视频的多帧对齐融合降噪, 五颜六色的光流图看起来很酷炫. 所以出于好奇, 看了一些关于光流的基本知识和经典文章, 下面做一些记录.
传统算法 – Lucas-Kanade
直观地想象一下, 针对这样一个问题: 追踪视频前后帧对应像素点的矢量位移, 需要先检测出前一帧的特征点, 再检测出下一帧的特征点, 并且需要把它们一一对应匹配起来, 对应的连线就是光流, 是一个长度为2的矢量[u, v], 分别代表在x, y轴方向的移动速度(单位时间内的位移). 如果需要求出所有像素点的光流, 就是稠密光流计算, 计算量比较大. 这里要介绍的是一种稀疏光流计算法, 只抽取某一些局部特征点, 计算少数点的光流.
为了简化问题, 针对光流问题有以下两个假设:
1. 像素点的强度(亮度, 或者可以理解成是颜色)在连续帧之间不会有剧烈的变化, 近似看成不变;
2. 由于大多数运动是物体的整体运动, 相邻像素之间可认为具有相似的运动, 近似看成相同的位移矢量.
根据假设一, 有如下等式成立,
$I(x, y, t) = I(x+dx, y+dy, t+dt)$
对上式右边做泰勒一阶展开, 并两边同除以$dt$,
$\frac{\partial I}{\partial x}\cdot\frac{dx}{dt} + \frac{\partial I}{\partial y}\cdot\frac{dy}{dt} + \frac{\partial I}{\partial t}\cdot\frac{dt}{dt} = \frac{\partial I}{\partial x}\cdot u + \frac{\partial I}{\partial y}\cdot v + \frac{\partial I}{\partial t} = 0$
上式中未知的就是要求的光流[u, v], 然而一个方程有两个未知数是未定的, 无法解出. 这时前面的假设二就用上了, 取相邻$3\times3$范围内的像素, 就有9个同上的等式, 解2个相同的[u, v], 是可以解出来的.
“Lucas-Kanade”算法采用最小二乘法, 拟合出最终的解:
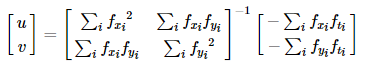
OpenCV实验
我采用OpenCV的光流API做了一些实验, 其中提供初始特征点的函数是cv2.goodFeaturesToTrack, 提供 “Lucas-Kanade”算法的函数是cv2.calcOpticalFlowPyrLK. 发现确实可以追踪关键点, 但是也存在一些问题: 一, 只针对小位移有很好的效果, 运动过大则容易丢失关键点; 二, 比较依赖于提供的初始点, 当初始点运动出了视频区域, 则无法继续追踪新的关键点, 需要通过其他API指定新的关键点.

OpenCV还提供了一些致密光流算法, 这里采用基于”Gunner Farneback”算法的函数cv2.calcOpticalFlowFarneback调用摄像头测了一把实时光流. 效果如下, 比稀疏点光流看起来要更加酷炫, 因为是在全局上的计算, 精度应该更高. 但缺点就是速度慢, 在实时视频上存在比较严重的卡顿, 看来应用到实际场景下应该是不大可能的, 除非移植到GPU平台上.

光流的可视化
不同于关键点检测, 语义分割等任务, 它们的输出只是一维的标量. 这里的光流, 是一个二维的矢量, 所以无法用简单的RGB域上的mask来表示, 所以得想其它表示方法. 在HSV域上, 有三个维度, H(Hue, 色调(比如红色黑色黄色等)), S(Saturation, 饱和度(比如深红浅红等)), V(Value, 明度(比如五彩斑斓的黑等)). 三个维度足够用来存储具有两个维度的光流, 具体的说, H用来存储光流失量的方向, S用来存储光流失量归一化之后的大小, V被固定成全黑或全白. 定性地来看, 在在下图轮盘上的颜色对应着速度方向, 如红色代表向右移动, 青色代表向左; 颜色饱和度越高, 代表速度越快; 纯白则代表是静止的背景.
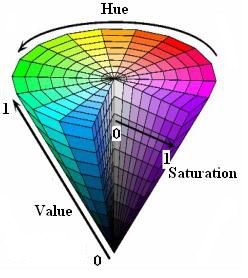
OpenCV提供了一系列的API用来颜色域上的转换, 具体过程如下:
1 | |
介绍完传统算法, 下面根据两篇具体的文章看看深度学习算法是怎么实现光流预测的.
FlowNet: Learning Optical Flow with Convolutional Networks (ICCV 2015)
这是用CNN以end-to-end方式预测光流的开山之作, 后面的FlowNet 2.0也是在其基础上做的延伸. 思考一下, 如何才能正确引导CNN去学习前后帧之间像素的位移? 暴力CNN的思路就是输入是前后连续两帧, 输出是光流, 这样纯粹地依靠数据来引导学习是否真的可行? 还是说应该针对前后两帧分别作处理, 然后手动设计一个匹配过程来计算光流更加贴近人类思考的国成? 文中针对这两种方式分别设计了两种不同的网络模型, 并进行了分析对比.
网络结构
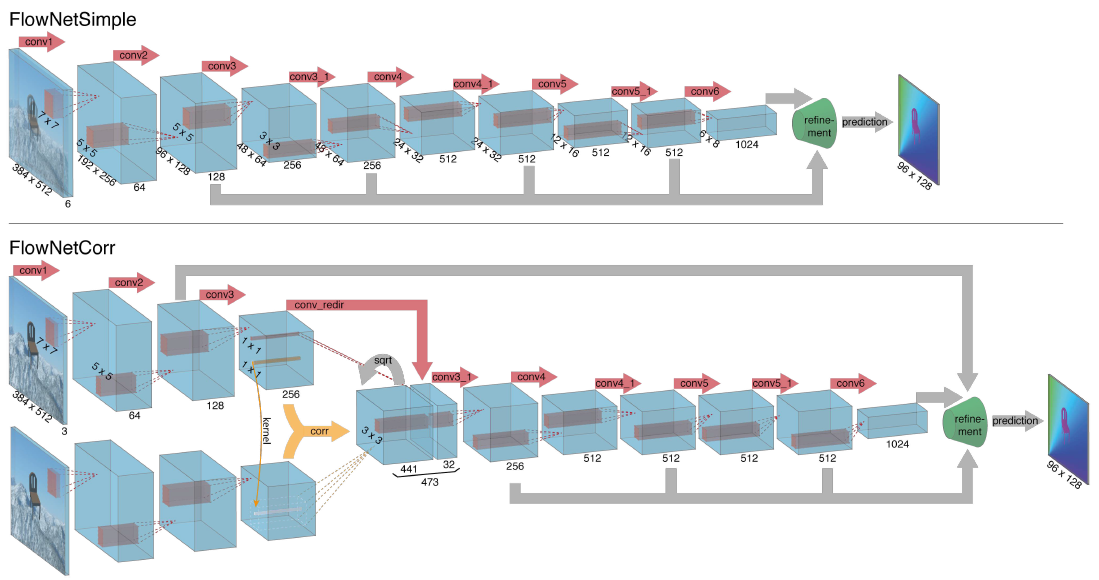
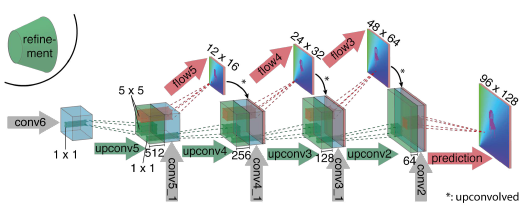 暴力CNN: 输入是连续的两帧RGB图concatenate在一起, 一共是6层channel; 输出是光流图, 猜测是2层通道. 其实就是U-Net的Encoder-Decoder + Skip connection结构. 思路很直接, 做法比较硬核.
暴力CNN: 输入是连续的两帧RGB图concatenate在一起, 一共是6层channel; 输出是光流图, 猜测是2层通道. 其实就是U-Net的Encoder-Decoder + Skip connection结构. 思路很直接, 做法比较硬核.
人工correlation CNN: 像前面那样暴力丢数据让网络去硬学输入和输出之间的联系, 可能没有学习到问题的本质. 所以在这里加了人工干预, 让连续两帧之间产生刻意的联系. 具体的来说, 两帧分别做两路输入, 然后在某一层级的feature上, 采用”人工卷积”让两路合并成一路, 剩下的结构与”暴力CNN”相同. “人工卷积”的操作如下, 即在两路feature上做空间卷积(图中黄色箭头部分).
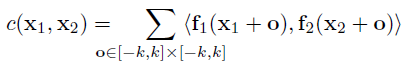 在第一帧的像素点上, 使用第二帧对应位置邻域上的feature值做相互的卷积操作, 以这种方式学习得到像素点在前后两帧间的差异. 这是一种无网络参数的操作, 不占显存.
在第一帧的像素点上, 使用第二帧对应位置邻域上的feature值做相互的卷积操作, 以这种方式学习得到像素点在前后两帧间的差异. 这是一种无网络参数的操作, 不占显存.
训练数据
真实场景下, 是无法标定光流的, 所以只能采用人造数据集的方式. 先给定设计好的运动, 这样光流其实就是已知的, 然后依据假设好的光流给定图片中物体的运动轨迹, 作为训练数据.
 上图中, 椅子其实是单独的贴图, 给定第一张图中椅子的仿射变换矩阵, 就能计算出第二张图中椅子的位置, 同时光流也能直接给出.
上图中, 椅子其实是单独的贴图, 给定第一张图中椅子的仿射变换矩阵, 就能计算出第二张图中椅子的位置, 同时光流也能直接给出.
模型结果及评价


以深度学习的方式, 达到了差不多接近于传统算法的效果. 虽然得分上略低, 但是文中argue说Note that even though the EPE of FlowNets is usually worse than that of EpicFlow, the networks often better preserve fine details. 文章的成功之处在于, 一是实现了端到端的CNN算法预测光流, 虽然得分不及传统算法, 但是也是开辟了一条新路径; 二是使用自制的数据集, 训练出来的模型在自然场景下也能适用, 这具有很强的现实意义. 给我们带来的启示是, 在训练模型时, 没有数据该怎么办? 数据没法标怎么办? 此文是”人工逆向造数据的成功典范”.
论文链接: FlowNet: Learning Optical Flow with Convolutional Networks
FlowNet 2.0: Evolution of Optical Flow Estimation with Deep Networks (CVPR 2017)
这篇文章是上一篇文章的进阶版, 作者是同一批人. 主要有三个改进: 一, 在网络结构上, 采用boosting的思想, 将FlowNet 1.0中的FlowNetSimple和FlowNetCorr两个基本网络重复堆叠在一起, 后面的学习器学习前面学习器产生的残差. 二, 对训练策略进行调整, 不让网络过早地接触太复杂的数据集, 从而避免学习到不本质的现象. 三, FlowNet 1.0对大运动敏感, 小运动效果不佳, 这与传统算法刚好相反, 而这里FlowNet 2.0针对小运动专门增加subnetwork提高小运动场景下的效果.
网络结构
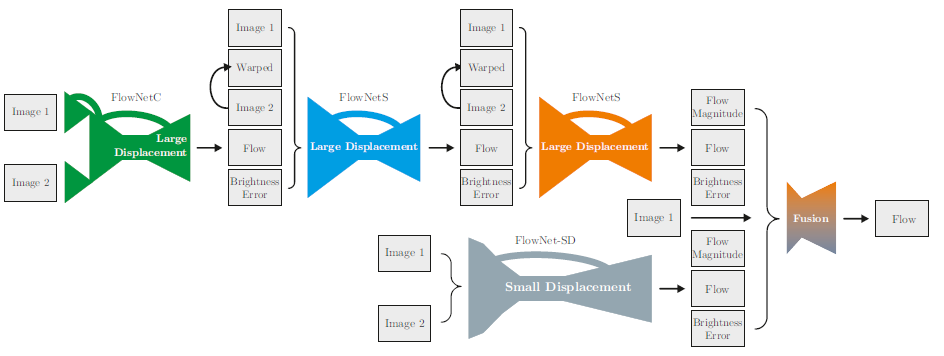 文中提到
文中提到All state-of-the-art optical flow approaches rely on iterative methods. Can deep networks also benefit from iterative refinement?, 借鉴了传统算法的迭代做法, 将多个子网络叠加在一起. 同时, 文中还提到: We conducted this experiment and found that applying a network with the same weights multiple times and also fine-tuning this recurrent part does not improve results (see supplemental material for details)., 也就是说, 简单地堆叠相同的网络其实并没有带来好处. 依据Boosting的思想, 基学习器之间还是存在差异比较好, 如果基学习器之间没有明显差距的话, 就跟把同一个网络来回循环一样了, 是得不到好的结果的.
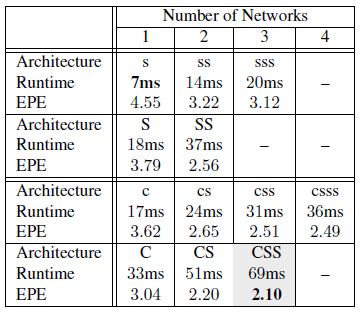 因此, 文中做了几组实验, 分别把
因此, 文中做了几组实验, 分别把FlowNetSimple(用s/S代表, 小写代表channel数更少)和FlowNetCorr(用c/C代表)反复堆叠数层. 最后发现确实是越深越好, 但同时计算时间也会越久.
在细节上, Boosting的残差体现在, 下一个子网络的输入是上一个网络预测的光流矫正后的图片(图中的Image2 + Warped), 即利用当前预测的光流对图片进行一次平移, 这时候frame2和frame1可能还没有完全对齐, 于是紧接着送入下一轮预测剩余的光流(残差).
$\hat I_i(x, y)=I_{i-1}(x+u_i, y+v_i)$
训练策略
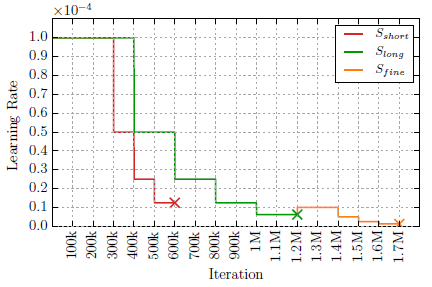
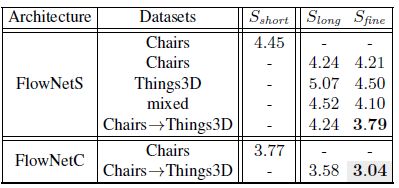 这里主要是learning rate schedule和训练集的加载方式. 总的来说, 训练迭代次数长的
这里主要是learning rate schedule和训练集的加载方式. 总的来说, 训练迭代次数长的fine tune方式带来的精度最高. 训练集方面, Chairs是自制的”漂浮椅子贴图”数据集, 表现形式比较简单, 主要是平面运动; 而Things3D是进阶3D版的”漂移椅子贴图”, 运动形式比较复杂, 存在三维变换和光线明暗变化. 最终, 先在简单Chairs上训练, 再到复杂Things3D上微调效果最好. 文中给的解释是, We conjecture that the simpler Chairs dataset helps the network learn the general concept of color matching without developing possibly confusing priors for 3D motion and realistic lighting too early, 即不能一上来就让网络学习太难的数据集, 要像教小学生一样循序渐进, 难度逐渐增加, 才能学习到问题的本质.
针对小位移的子网络
像素具有较小的运动时, 可能处于亚像素级别, 这时候噪声的影响就不可忽略. 因此子网络在FlowNetSimple基础上, 替换第一层7x7Conv为多个3x3Conv, 在反卷积之前增加Conv, 成为FlowNet2-SD. 我的理解是, 这么做其实就是加深了网络, 让感受域增加, 这样局部的噪声就会被平均掉. 同时对主干的网络针在小位移的数据集上进行微调. 最后进行融合, 形成最终的FlowNet 2.0.
模型效果及思考
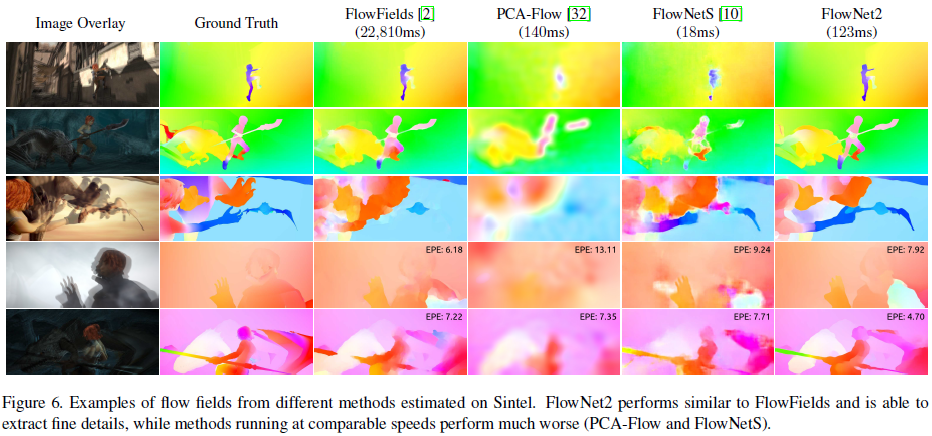
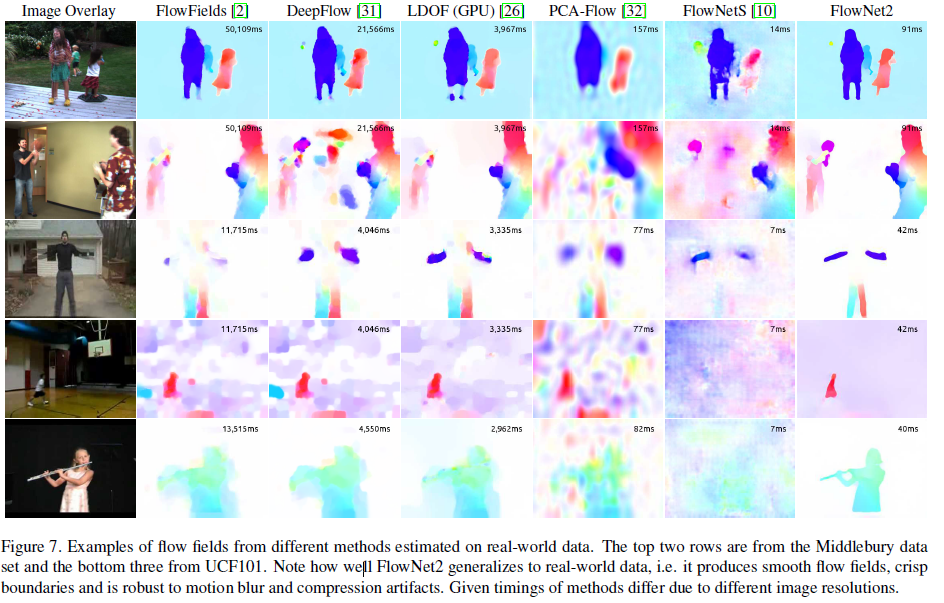
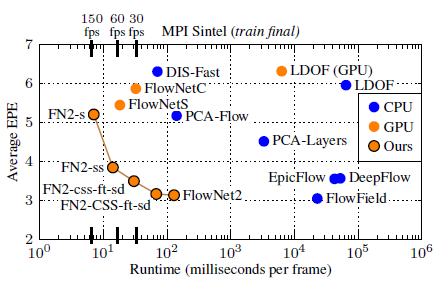
模型在自制数据集和真实场景下都有很好的结果, 边缘和细节比较清晰, 同时速度还比传统算法快, 实现了SOTA.
整篇文章读下来, 感觉就是在FlowNet 1.0的基础上”调参”, 实打实地作为一个算法工程师在调参. 调网络结构、channel数, 调数据, 调学习率, 各种fine tune. 总结一下, 该文是”如何科学调参的正确示范”.
论文链接: FlowNet 2.0: Evolution of Optical Flow Estimation with Deep Networks
参考资料:
OpenCV关于Optical-flow的例子:
https://docs.opencv.org/3.4.5/d7/d8b/tutorial_py_lucas_kanade.html
FlowNet 2.0站点:
https://lmb.informatik.uni-freiburg.de/Publications/2017/IMSKDB17/