纹理(texture)和形状(shape)信息对CNN的认知影响哪个大?就人类而言,披着象皮的猫咪,人类依然能依靠形状轮廓辨识出这是猫。而对CNN而言,实验发现它对这种对抗样本的辨识能力很差,容易被错误的纹理信息所误导,而无法从正确的形状轮廓中提取信息,在需要依靠物体轮廓定位的detection和segmentation等任务上,这种缺点是会显著降低模型精度的。因此有必要引导CNN去学习正确的图像信息。
问题背景
paper地址:IMAGENET-TRAINED CNNS ARE BIASED TOWARDS TEXTURE; INCREASING SHAPE BIAS IMPROVES
ACCURACY AND ROBUSTNESS(ICLR 2019)
在CNN发展的初期,有一个默认的共识,就是CNN的浅层提取的是点、线这样的local low-level feature,深层提取的是整体轮廓或与语义相关的global high-level feature,CNN从图片中看到的是形状信息(shape),这是shape hypothesis。
那么图片的纹理信息(texture)就是无用的吗?也有一部分paper证明,仅依靠局部的纹理信息就能够提供足够的信息进行分类,他们认为纹理信息应该比形状信息更重要,这是texture hypothesis。
针对这样的两种观点,作者针对图片的shape和texture两种变量做了对比实验,采用transfer learning GAN的方法构造了不具有特定texture、但具有物体原本shape的分类数据集 Stylized-ImageNet(SIN),经过实验发现,CNN的确对texture更为敏感。但这种错误的敏感可以通过SIN数据集给纠正过来,变得对shape更为敏感,从而对图片纹理噪声更为鲁棒,在classification和detection等任务上取得更高的精度。
数据集Stylized-ImageNet

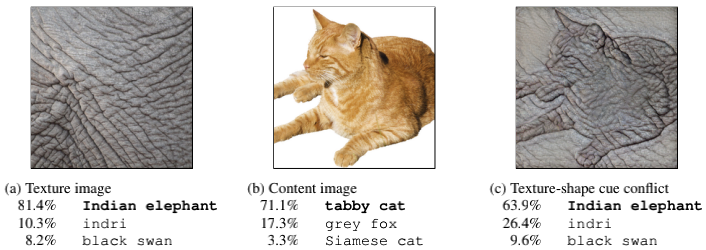
 如上图的实例,采用AdaIN style transfer(Huang & Belongie, 2017)算法,以ImageNet为基础,每张图片只迭代一次,这样既能保证原图与语义信息相关的shape保持原状,又能使它的texture具有不可辨识性,相当于只保留了shape,把texture变成了随机噪声,保持单一变量。
如上图的实例,采用AdaIN style transfer(Huang & Belongie, 2017)算法,以ImageNet为基础,每张图片只迭代一次,这样既能保证原图与语义信息相关的shape保持原状,又能使它的texture具有不可辨识性,相当于只保留了shape,把texture变成了随机噪声,保持单一变量。
实验结果
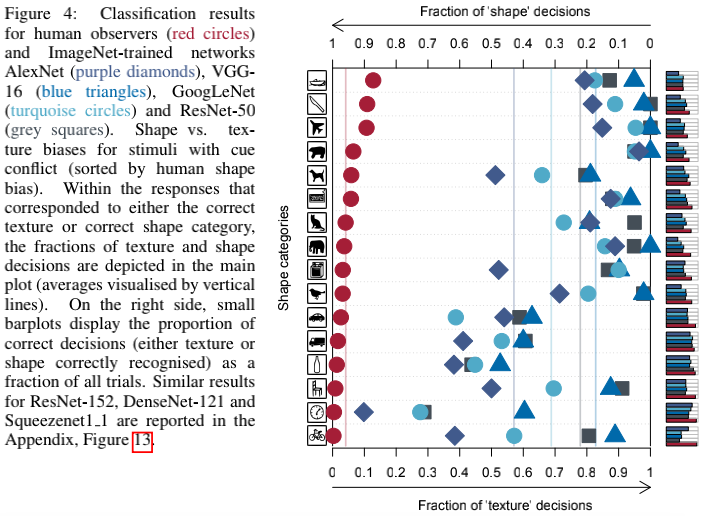 (a)以ImageNet为训练集,Stylized-ImageNet为测试集,人类水平和各种CNN的分类结果如上图(baseline)。结果显示,人类在面对这样的迷惑性图片时,依然倾向于凭借shape来做出判断(95.9%的倾向),而CNN则倾向于凭借texture来做出判断(VGG-16: 17.2% shape vs. 82.8% texture; GoogLeNet: 31.2% vs. 68.8%; AlexNet: 42.9% vs. 57.1%; ResNet-50: 22.1% vs. 77.9%),与人类完全相反。注意右边小的条状图才是预测精度,其实都很低。
(a)以ImageNet为训练集,Stylized-ImageNet为测试集,人类水平和各种CNN的分类结果如上图(baseline)。结果显示,人类在面对这样的迷惑性图片时,依然倾向于凭借shape来做出判断(95.9%的倾向),而CNN则倾向于凭借texture来做出判断(VGG-16: 17.2% shape vs. 82.8% texture; GoogLeNet: 31.2% vs. 68.8%; AlexNet: 42.9% vs. 57.1%; ResNet-50: 22.1% vs. 77.9%),与人类完全相反。注意右边小的条状图才是预测精度,其实都很低。
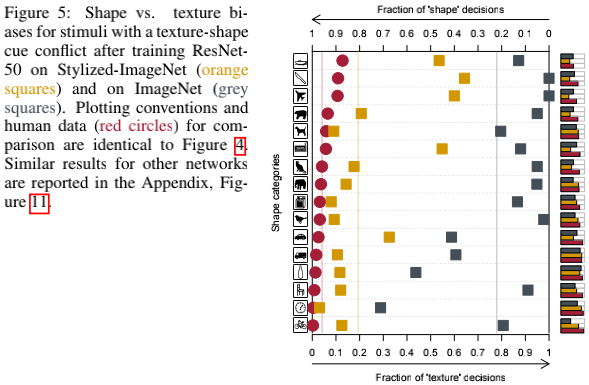 (b)改成以Stylized-ImageNet为训练集后,结果如上图。可以看到CNN的预测依据明显向shape靠拢了(橘黄方块),说明该训练集能够引导CNN学习shape信息,降低其对texture的依赖。因为此训练集中的texture信息已经无法使用了,是与物体本身无关的随机噪声,而只剩下尚保留的物体shape信息。
(b)改成以Stylized-ImageNet为训练集后,结果如上图。可以看到CNN的预测依据明显向shape靠拢了(橘黄方块),说明该训练集能够引导CNN学习shape信息,降低其对texture的依赖。因为此训练集中的texture信息已经无法使用了,是与物体本身无关的随机噪声,而只剩下尚保留的物体shape信息。
数据集联合训练
前面的实验证实了Stylized-ImageNet数据集能够提升CNN对shape的关注度,减少对texture的关注度。那么能否利用这个特性,提升CNN在标准数据集中的精度?
作者做了对比实验,在Stylized-ImageNet(SIN)上训练得到的模型在ImageNet(IN)上效果变差了,这是很自然的。
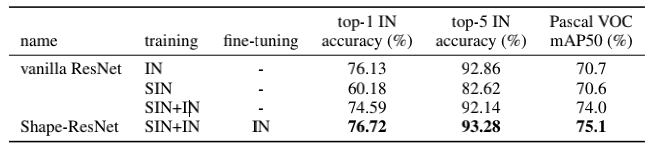
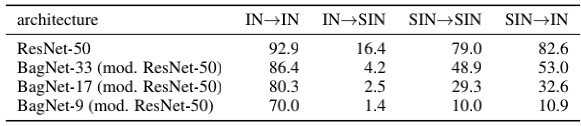 所以为了能在IN上利用SIN得到性能的提升,作者将SIN和IN数据集联合起来训练,并做了消融对比。发现即使同时使用两个数据集,精度依然有所下降,但是如果紧接着在IN上fine tune,就能得到更好的结果。另外,不仅是classification任务,在VOC上的detection精度也能得到提升(注意,无需fine tune也能有提升),说明这种需要localization的任务从“对shape的更多关注”中受益了。
所以为了能在IN上利用SIN得到性能的提升,作者将SIN和IN数据集联合起来训练,并做了消融对比。发现即使同时使用两个数据集,精度依然有所下降,但是如果紧接着在IN上fine tune,就能得到更好的结果。另外,不仅是classification任务,在VOC上的detection精度也能得到提升(注意,无需fine tune也能有提升),说明这种需要localization的任务从“对shape的更多关注”中受益了。
对图片噪声的鲁棒性
既然SIN能够让CNN减轻对texture的过度关注,是不是意味着CNN对图片纹理信息像素级的扰动和噪声能更加鲁棒?是的。
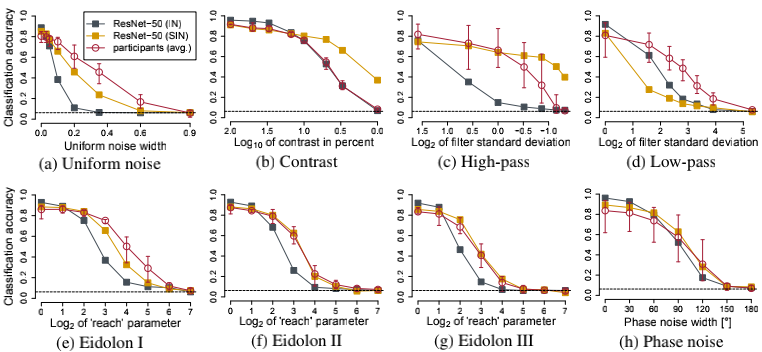
 作者使用多种图片增广手段,如uniform or phase noise, contrast changes, high- and low-pass filtering or eidolon perturbations,测试SIN下的CNN对这些操作的鲁棒性,结果如下图。在大多数操作下,SIN显示出了比IN更好的鲁棒性,唯独在低通滤波下,效果反而比IN的差。这也可以理解,低通滤波抹去了图片的高频纹理信息,迫使IN下的CNN减轻了对texture的过度关注,增大了对shape等边缘信息的关注,作用跟SIN有些类似(这也说明了喂给CNN的图片先Gaussian blur一把有多么重要!)。
作者使用多种图片增广手段,如uniform or phase noise, contrast changes, high- and low-pass filtering or eidolon perturbations,测试SIN下的CNN对这些操作的鲁棒性,结果如下图。在大多数操作下,SIN显示出了比IN更好的鲁棒性,唯独在低通滤波下,效果反而比IN的差。这也可以理解,低通滤波抹去了图片的高频纹理信息,迫使IN下的CNN减轻了对texture的过度关注,增大了对shape等边缘信息的关注,作用跟SIN有些类似(这也说明了喂给CNN的图片先Gaussian blur一把有多么重要!)。
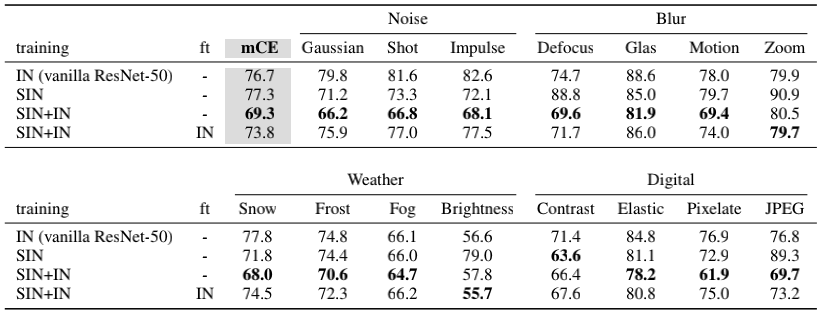
 作者还测试了在更多图片噪声场景(噪声、模糊、雪雾天、降采样)下的结果。此时,SIN和IN联合训练(不fine tune)的平均误差最小,说明SIN在极端场景下具有很好的应用前景。
作者还测试了在更多图片噪声场景(噪声、模糊、雪雾天、降采样)下的结果。此时,SIN和IN联合训练(不fine tune)的平均误差最小,说明SIN在极端场景下具有很好的应用前景。
额外思考
作者还做了一份小的验证工作,使用感受域很小的BagNet(9、17、33)做了测试,发现它们虽然在IN上效果还行,但在SIN上的效果很差。作者的解释是这样的:This is a clear indication that the SIN data set we propose does actually remove local texture cues, forcing a network to integrate long-range spatial information.,认为是因为SIN没有texture信息,这种texture以前只需要很小的感受域就能捕捉到了,而现在只有更大感受域才能捕捉到的shape信息,那些感受域小的网络当然就不行了。
基于这样的认知,可以大胆推测有如下的原理。小的感受域能捕捉texture信息,大的感受域能捕捉shape信息,而网络在一开始训练时往往感受域很小(见Effective receptive field中的分析),此时很容易学习到texture信息,同时网络还有一个特性:非常容易在初期记住容易学习的东西,一旦网络在初期学得这些信息后,在后期的训练中往往很难纠正回来,也就是说一开始如果学得太快了,过分关注了texture信息,后续的shape信息就难以学进去了。而SIN恰好能解决这些问题,把texture信息给抹去,让其去学习shape信息。
总结一下,SIN使得CNN更为关注语义轮廓信息,因此与localization相关的任务如detection和segmentation都能从中受益。另一方面,极端图片噪声场景下,SIN也能增加CNN对噪声的鲁棒性,是否有可能应用在超画质、降噪等领域?值得思考和调研。