BN作为神经网络的万金油,能够显著加速模型训练,并提升模型训练的稳定性和最终精度。它在一个batch的数据上做归一化,把数据重整化为零均值标准方差的分布。问题在于,如何取batch size的大小?batch size太大,做归一化绰绰有余,且训练时间能大幅缩短,但是GPU显存吃不消,只能在多卡上做数据并行训练,多卡数据间如何求BN也是个问题,同时由于一个epoch内steps少了,模型迭代次数不够,也会掉点;batch size太小,数据间方差波动太大,不具有统计性,此时做BN并不能对数据做有效归一化,也会影响最终精度。本文就这些问题做一些文献调研和记录,涉及Linear Scaling Rule、Gradual warmup、Cross-GPU BN、Cross-Iteration BN、Filter Response Normalization Layer等。
G/D/C-IoU loss
在detection任务中,需要对候选框的坐标位置进行回归。常用的loss有L1、Smooth L1、L2,但它们的参数都是未归一化的,容易受框的尺寸影响,后来又有IoU这种归一化过的尺寸无关loss,但它也有优化缓慢、未重叠框无法优化等缺点,于是又有人在IoU的基础上进行各种改进,本文将会介绍这些改进版的IoU loss。
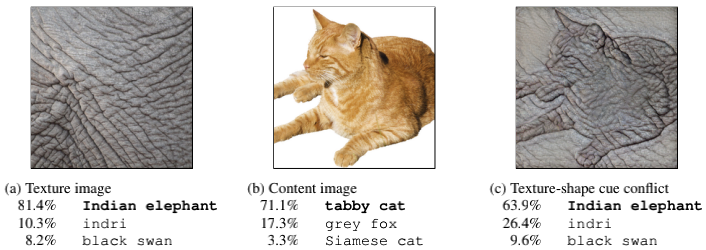
texture-shape cue conflict of CNN
纹理(texture)和形状(shape)信息对CNN的认知影响哪个大?就人类而言,披着象皮的猫咪,人类依然能依靠形状轮廓辨识出这是猫。而对CNN而言,实验发现它对这种对抗样本的辨识能力很差,容易被错误的纹理信息所误导,而无法从正确的形状轮廓中提取信息,在需要依靠物体轮廓定位的detection和segmentation等任务上,这种缺点是会显著降低模型精度的。因此有必要引导CNN去学习正确的图像信息。
YOLO v1/v2/v3/v4
YOLO v1-v3的作者,Joseph Redmon大神,因为考虑到自己的研究成果会被用于军事用途和个人隐私领域,因此在2020年2月宣布退出CV界,可谓是非常洒脱了。但YOLO系列并没有因此停止更新,在随后的4月,YOLO v4由他人接棒发表并得到了大神本人的认可。全文涉及到非常多的detection领域的历史研究成果,可谓是集大成者,一开始初看简直是眼花缭乱,也真心感叹现在水论文越来越不容易了。为了理解这篇paper也补看了很多相关的历史paper,中间又断断续续地受到疫情和毕业手续的影响,现在终于能静下心来好好地记录一下相关的知识。全文涵盖的知识点比较多且杂,但也是成体系的,久远的YOLO v1-v3会一带而过,重点放在v4上(李鬼版的v5请忽略)。
配置VS Code - 进阶
前段时间服役了多年的macbook突然宕机了,发现是硬盘坏了,彻底坏了的那种,遂重新装机,重新配环境。在配环境的过程中发现很多低端重复性的操作简直是浪费时间,尤其是基于vscode这种高自由度IDE的环境配置,所以在此做一些记录,希望以后在迁徙生产力的时候能少费功夫。主要有vscode上C++、OpenCV、code runner、setting sync、右键从文件夹进入等配置。
intra-class / inter-class loss
因为疫情的原因,在家滞留了大半年,期间在家用一个半月的时间写完了硕士毕业论文,现在算是慢慢闲下来了,终于可以随便看看paper写写博客了。找了一篇最近预发表的CNN综述(2020年4月),通篇读下来还是发现了一些基础知识上的盲区,比如分类问题上的loss除了有最常见的交叉熵,还有进一步考虑类内距离和类间距离的loss,主要用于人脸识别和ReID等领域。下面针对这方面的工作做一些归纳和记录。
2019年终总结
2019年, 从研二下学期到研三上学期, 从实习到找工作到写论文投稿, 经历了很多事情. 虽然我不是一个怀旧的人, 但还是有必要在这里记录一下比较难忘的事, 作为经验, 引出接下来的2020年要做的事.
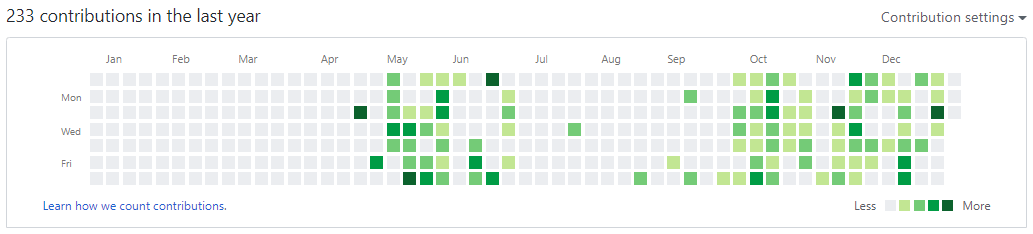
回忆主要依据Github上的Contribution展开, 可以从下图看到, 主要有五个阶段: 一, 离校实习(2019.01.07-04.15), 这段时间主要是维护在GitLab上的公司repo, 所以Github上的Contribution是一段空白; 二, 返校做硕士课题(04.15-05.31), 做了一个用于多相流流场分割的模型, 这段主要是在维护数据和模型两个独立的repo; 三, 准备秋招(06.01-09.31), 这段时间主要在LeetCode上刷题, 零星的几个Contribution是在维护个人简历的repo; 四, 写文章(10.01-11.01), 这段时间主要在维护论文的LaTexrepo; 五, 投稿(11.01-12.26), 这段时间对硕士课题相关的课题repo有一些修补, 在等待小老板改文章的过程中浪费了很多时间.
Matplotlib -- SCI论文绘图配置
前一阵子忙着修改论文, 最近完成了初稿, 为了后期能复现一些结果, 就把文献、代码、数据以及后处理等过程都做了存档. 其中, 所有的的示意图都是用PPT制作的, 所有的数据图都是用Matplotlib画的, 二者自由度都很高, 这也意味着有些地方需要人为精细地控制, 下面针对写Paper的大概流程配置和Matplotlib制作科研论文用图的设置做一些记录.
Image inpainting using CFD methods
无意间翻阅了OpenCV计算摄影学篇章的教程, 主要有三部分: Image denoising, Image inpainting和HDR, 基本上对应着组里ISP方向现有的研究内容. 其中, 提到了一种使用计算流体动力学(Computational Fluid Dynamics/CFD)的方法来解决inpainting问题, 而CFD恰巧是我所熟悉的, 所以就找了对应的文献简单复现了一下, 下面做一些记录. 需要注意的是, 这里所涉及的都是传统算法, 与深度学习方法无关.
Effective receptive field
针对mage classification, semantic segmentation等任务, 需要感受域越大越好, 这样在high-level的feature上看到的原始输入像素范围更大, 更有利于做出全局判断. 在detection等任务上, 为了检测到不同尺度大小的物体, 需要在不同感受域大小的feature上分别做检测. 但是, 感受域究竟需要大到多少? 真的是越大越有效吗? 针对这些问题调研了相关文献, 做了以下整理和记录.