这是李飞飞课题组的一篇文章, 与传统的pixel-wise loss不同, 用feature loss来衡量距离, 在迁移学习和超分辨率有一些用途. 突然回想起来以前同事在单帧超画质的模型中用到过, 当时还不知道是什么东西, 现在对文章内容做一些介绍.
研究内容
- Perceptual Loss(感知损失函数): 使用一种新的Perceptual Loss, 来作为图像转换任务(风格迁移, 超分辨率, 去噪等)中的训练方向, 能够有更高的计算效率和更鲁棒的效果.
文章创新点
- Perceptual: 在计算机视觉任务中, 需要把输入图片转化成目标图片, 这个目标图片不一定是精确的某张图, 可能是指定的图像风格迁移, 超分辨率等目标. 传统的pixel-wise loss(L1/L2/Cross entropy等)旨在把output尽可能地拉向target, 追求像素级的值相等. 然而并不是pixel-loss低, output和target就会差距大. 例如, target存在一个整体小的平移时, pixel-loss也会很大, 但是此时平移后的图像和原图本质上没有任何区别. 因此, 在侧重追求视觉效果更高level(整体风格, 颜色, 纹理等, 可概括称之为perceptual(感知))的任务中(如style transfer和super resolution), 以feature作为loss更能反映实际的优化方向.
系统框架
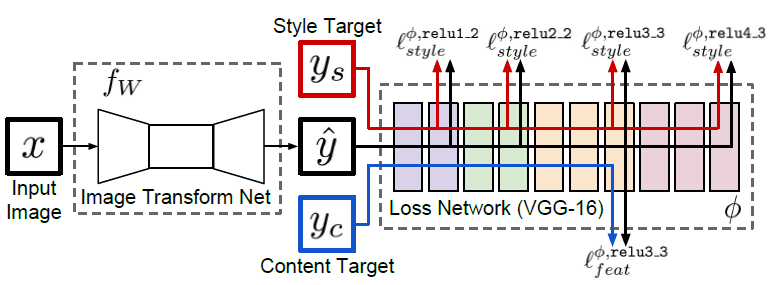
- Loss Network: 使用一个在ImageNet上预训练好的VGG, 冻结参数, 作为feature extractor. 把output和target都送进VGG, 并在不同的level提取feature作为计算loss的依据. 针对style transfer问题, 不同level feature对应着不同尺度的风格(低维的点线和高维的颜色风格等), 因此style target在各个level的feature都被抽取来计算loss, 同时content target在某一特定level的feature被抽取作为基本图片内容信息; 针对super resolution问题, 只关注content信息, 没有style target, 因此只从content target在某一特定level抽取的feature计算loss.
- Transform Network: 可以是任何image-to-image形式的模型. 具体任务使用具体的对应模型.
损失函数
- content loss. 其实就是L2 loss, 只不过是feature层面的L2 loss. 与直接的pixel-wise loss相比, 这样的好处是既避免了output和content target变得过分相似, 又能引导output的content信息.
这里的$\phi_j(\hat y)$和$\phi_j(y)$分别指output在VGG中的feature和content target在VGG中的feature.
上图是提取content target在不同level的feature作为loss所得到的结果. level不同, 保留的信息也不同.
- style loss. 这里其实引用了前人[1][2]的工作. 定义了一个
Gram matrix来衡量每个张量的无中心协方差大小, 原文给的解释是It thus captures information about which features tend to activate together.如果输入feature的维度是$C\times H\times W$, 那么该矩阵的维度就是$C\times C$. 这样做带来一个优势, 即使output和style target的shape不一样, 但依然可以计算loss.具体到代码中
其中, $\psi$指的就是前面的$\phi_j$. 分别计算output feature和style target feature的Gram matrix, 然后计算二者的Frobenius 范数距离, 即为style loss:
上式中, Frobenius 范数距离的形式如下,
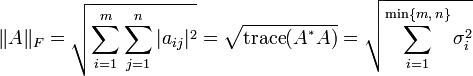
以style target在不同level的feature作为loss得到的结果. 不同level反映不同尺度的特征.
模型效果
- style transfer定性效果.
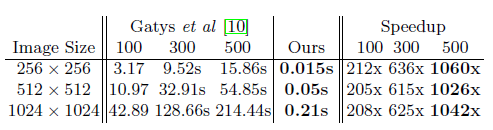
- style transfer定量速度比较.
- super resolution定性&定量比较.


思考
- 对于风格迁移问题, 需要提取特征作为目标方向容易理解, 文中实现了与其他方法相比较好的效果且更高的计算效率, 这是很positive的. 但是对于超画质, 需要的就是pixel-wise accuracy, 为何用perceptual loss会有更好的效果?
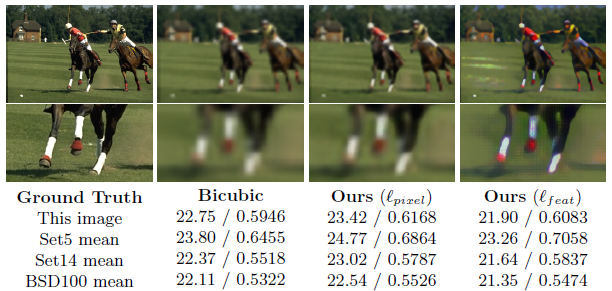
– 文中给的解释是:the use of perceptual loss functions allows the trans-fer of semantic knowledge from the loss network to the transformation network.即从VGG中提取的feature包含了一些先验的语义信息, 对超画质中物体的边缘纹理等的预测有帮助作用.The L_{pixel} loss gives fewer visual artifacts and higher PSNR values but the L_{feat} loss does a better job at reconstructing fine details, leading to pleasing visual results.下图是文中针对这一点解释所举的例子, 虽然定量分数更低, 在是在感官上, 图中的物理边缘更清晰, 人为视觉效果更好,suggesting that the L_{feat} model may be more aware of image semantics".
- 对于超画质问题, 究竟需要取什么level的feature作为loss合适?
– 文中并未提及该点, 猜测是基于经验和调参. 个人觉得应该是取对应着线条轮廓那个level的feature. level太低, 对应的是local级别的纹理信息, level太高, 对应的是global级别的语义信息, 应该需要的是对应着语义信息的轮廓线条信息, 所以level不能太高也不能太低.