因为在做硕士课题的过程中碰到了一些时序上的多帧处理, 就采用了Encoder-Decoder + ConvLSTM cell来做时序上的演化. 调研了一些文献, 发现相关的工作确实比较少, 大多集中在Image to caption, video object segmentation, semantic instance segmentation方面, 且大部分发表在早期的2015-2016年间, 随后都转向attention的研究工作了. RNN存在占用显存大、超长时记忆缺陷的问题, 做NLP的早已全面抛弃RNN转向attention的怀抱, 这些年CV方面也慢慢地向attention靠拢, 以后是个趋势, 所以学习了一下attention到底是个什么东西, 下面做一些记录.
我理解的
Attention
虽然自己完全不懂NLP, 但是attention最初起源于NLP的应用, 所以有必要在这里提一下. 这里举一个常见的例子, 在NLP的不定长时序输入中, I come from {China}, ... and i speak {Chinese}., 这里的Chinese其实跟前面出现过的China关系最大, 跟离它最近的speak反而关系不是最大, 但在RNN/LSTM中, 由于存在着长期遗忘的特性, 当Chinese和China之间的距离很远时, 它们二者的相互影响比较弱, 可能会被误判成English这类的. 所以为了解决这个问题, 需要人为地加强Chinese和China之间的联系, 让它们之间的权重比较大并占据主导地位, 即pay more attention to "China", 这就是字面上attention的理解.
在CV中也存在同样的问题, 图像中可能存在多个主体, 但我们最想关注的可能只是其中某一个主体, 这个时候就需要针对该主体做突出的强调, 让我们的网络更多地去关注(attention)该特定的主体. 直白地说, attention map就是权重图或者说是热力图. 那这跟convolution feature map有什么区别呢? 好像没太大区别, 本质是差不多的. feature map有或大或小的权值, 对应着给输入施以不同大小的权重, 但区别就在于feature map作用于整个global image, 其中存在着很多不相干的信息冗余. 而在attention map中, 由feature map中的权重经Softmax后产生的attention score介于0-1之间, 很小的attention score会把不相干的信息去除, 把相干的信息权重进一步提高, 相当于在feature map的基础上做二次强调处理. 下图便是一些直观的attention map.

下面, 就根据三篇具体的文章看看attention在CV中具体是怎么应用的.
Diagnose like a Radiologist: Attention Guided Convolutional Neural Network for Thorax Disease Classification
这是一个图像分类问题, 通过attention机制让模型更多地去关注某一特定区域的图像, 来判断病理图像到底属于哪一种疾病.
网络结构及训练策略
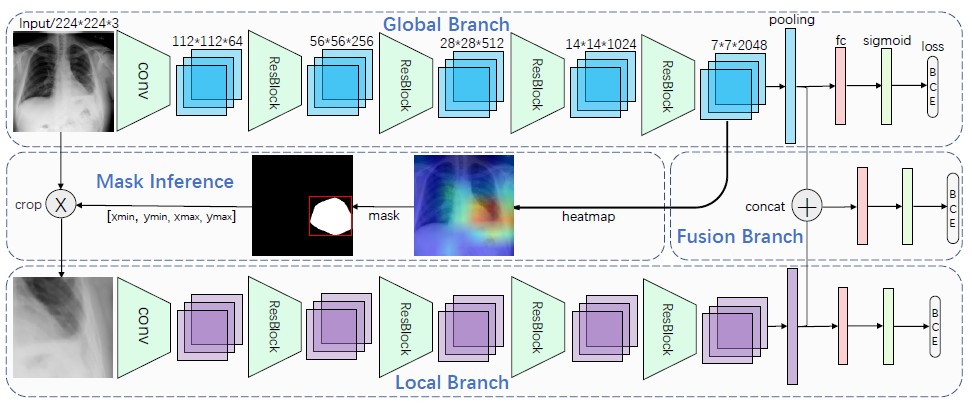 三个分支:
三个分支: Global branch, Local branch和Fusion branch. 其中Local branch被认为是attention的具体实现. 模型采用分段训练的方法, 先单独训练global branch, 训练完成后global branch最末端的feature被认为是每一类疾病的probability score, 或者说就是attention map或heat map. 当然, 这里不是简单地直接采用convolution feature map, 而是做了一个适当转化:
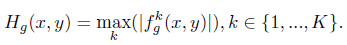 在每个pixel的位置上, 取所有
在每个pixel的位置上, 取所有channel上的最大值作为attention map的值, 有点像point-wise convolution的思想, 只不过这里只是挑出了最大值, 以此来表达最重要的联系. 得到attention map后就好说了, 依据一个阈值来把attention map二值化, 得到一个mask:
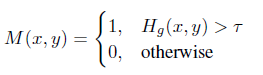
 再依据mask对
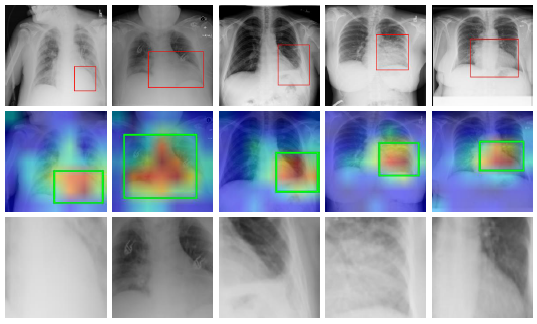
再依据mask对Global input做crop, 即只抠出attention map中attention score最高的区域送入Local branch, 这些区域是影响最终分类的最重要区域. 然后再单独训练Local branch. 最后, 还要单独训练一次Fusion branch.
模型评价
比较硬核的attention, 直接以0/1的attention score来分辨重要性, 这是一种hard attention. 再站在更高的角度想一想, 这是不是一种类似于ResNet的skip connection?
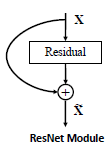
Global branch相当于Residual module, Local branch相当于skip connection. 但二者明显的区别是, ResNet认为skip connection是用来加强梯度的流动, 最后两个分支合并时用的add而不是multiply. 而这里的分支合并用的是multiply.
再来想一想, 在图像分割领域, FCN/U-Net/DeepLab中不同level的feature concatenate是不是也是类似于这种attention的形式? 只不过它们都没有刻意去”突出重要的部分, 削弱冗余的部分”, 只认为是一种local texture information和global semantic information的聚合.
Squeeze-and-Excitation Networks (CVPR 2018)
前面提到的是一种hard attention, 与之类似的还有soft attention. 接下来的这篇文章通过改造ResNet的residual module, 实现了一种类似于ResBlock的attention block, 突出the channel relationship.
网络结构
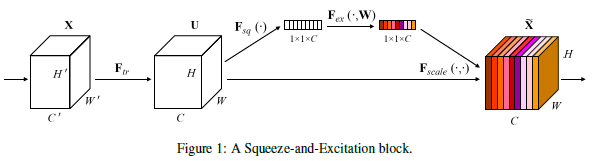 是不是很像
是不是很像ResBlock? 其中包含着四个操作.
$F_{tr}$: 其实就是一个普通的convolution, 但是作者强调the channel dependencies are implicitly embedded in it, but these dependencies are entangled with the spatial correlation captured by the filters., 意思是channel dependencies和spatial correlation纠缠在一起, 所以为了突出the channel relationship就有了后面的这些模块.
$F_{squeeze}$: 名字起得花里胡哨, 其实就是一个channel-wise global average pooling. 并给每个channel起了个包装名叫local descriptors.
$F_{excitation}$: 两层FC layers, 作用在前面$F_{squeeze}$的输出上, 相当于把channel wise的信息给打乱并连接到一起. 后面接一个Sigmoid对权重做一个二值分化.
$F_{scale}$: 其实就是一个channel-wise multiply, 把每一个channel上学习到的不同的权重赋予skip-connection的输入.
文中针对该模块的功能, 给出的解释是we propose a mechanism that allows the network to perform feature recalibration, through which it can learn to use global information to selectively emphasise informative features and suppress less useful ones. 关键词是feature recalibration, 这即是attention所在.
模型思考
与上一篇中提到的猜想类似, attention确实类似于ResNet中的skip connection. 所以作者也将此模块嵌入到了ResBlock和Inception block中.
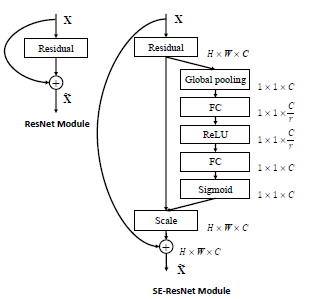
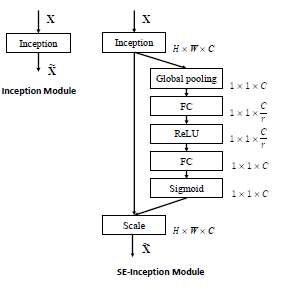 仔细看一看,
仔细看一看, attention的机制具体体现在Global pooling和Sigmoid这两个操作上, 让大的权重更大 来占据主导地位, 让小的权重更小来削弱信息冗余. 这些权重是通过两层FC layers来自己学习到的, 是一种端到端的训练, 不需要像上一篇文章中那样需要分几个阶段来生成attention map.
论文链接: Squeeze-and-Excitation Networks
Stand-Alone Self-Attention in Vision Models (NIPS 2019)
与上一篇类似但不同, 上一篇的squeeze-excitation block需要依附于传统convolution, 本篇提出了一种新的attention block可以完全代替convolution操作.
网络结构
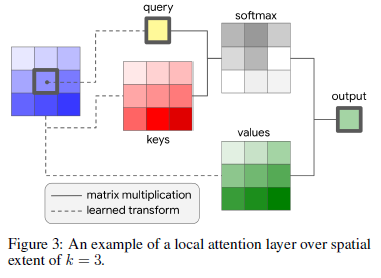 同
同convolution类似, 在一个邻域内, 针对输入做线性变换得到queries, keys和values, 然后在这三者的基础上做矩阵操作, 得到最终的结果. 这三者的公式如下, $W_Q, W_K, W_V$即是学得的参数.
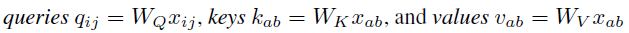 还需要考虑空间信息, 因此邻域内的像素距离也被计算在内.
还需要考虑空间信息, 因此邻域内的像素距离也被计算在内.
 最终的计算公式如下, 在每个pixel上都执行该操作, 权值是共享的. 但在每个channel上是独立进行的.
最终的计算公式如下, 在每个pixel上都执行该操作, 权值是共享的. 但在每个channel上是独立进行的.
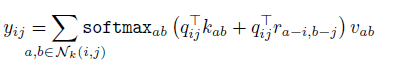
模型思考
其实这篇文章不是很懂, NIPS上的很多文章都比较简短, 细节也没说清楚, 需要比较多的预备知识. 比如这里的queries, keys和values到底是啥, 我目前还不太了解, 这里有一个lilianweng’s blog和Jay Alammar’s blog可供日后学习. 总之, 模块中也存在skip connection, 也有Softmax等二值分化操作.
论文链接: Stand-Alone Self-Attention in Vision Models
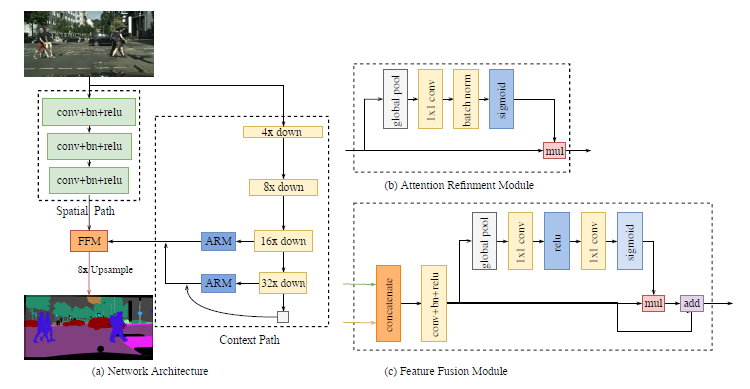
虽然attention相关知识挺深的, 但是本文的目的不在于覆盖到所有范围, 只是了解一下attention的思想到底是什么, 至于具体应用, 还需要以后继续学习. 很多以前不懂的文章, 现在也能够理解其中attention mechanism了. 比如很久以前读过的轻量级语义分割模型旷视-EECV-2018-BiSeNet, 里面就用到了attention block, 现在就可以理解了.
参考资料:
Self-Attention In Computer Vision: https://towardsdatascience.com/self-attention-in-computer-vision-2782727021f6
The fall of RNN / LSTM: https://towardsdatascience.com/the-fall-of-rnn-lstm-2d1594c74ce0